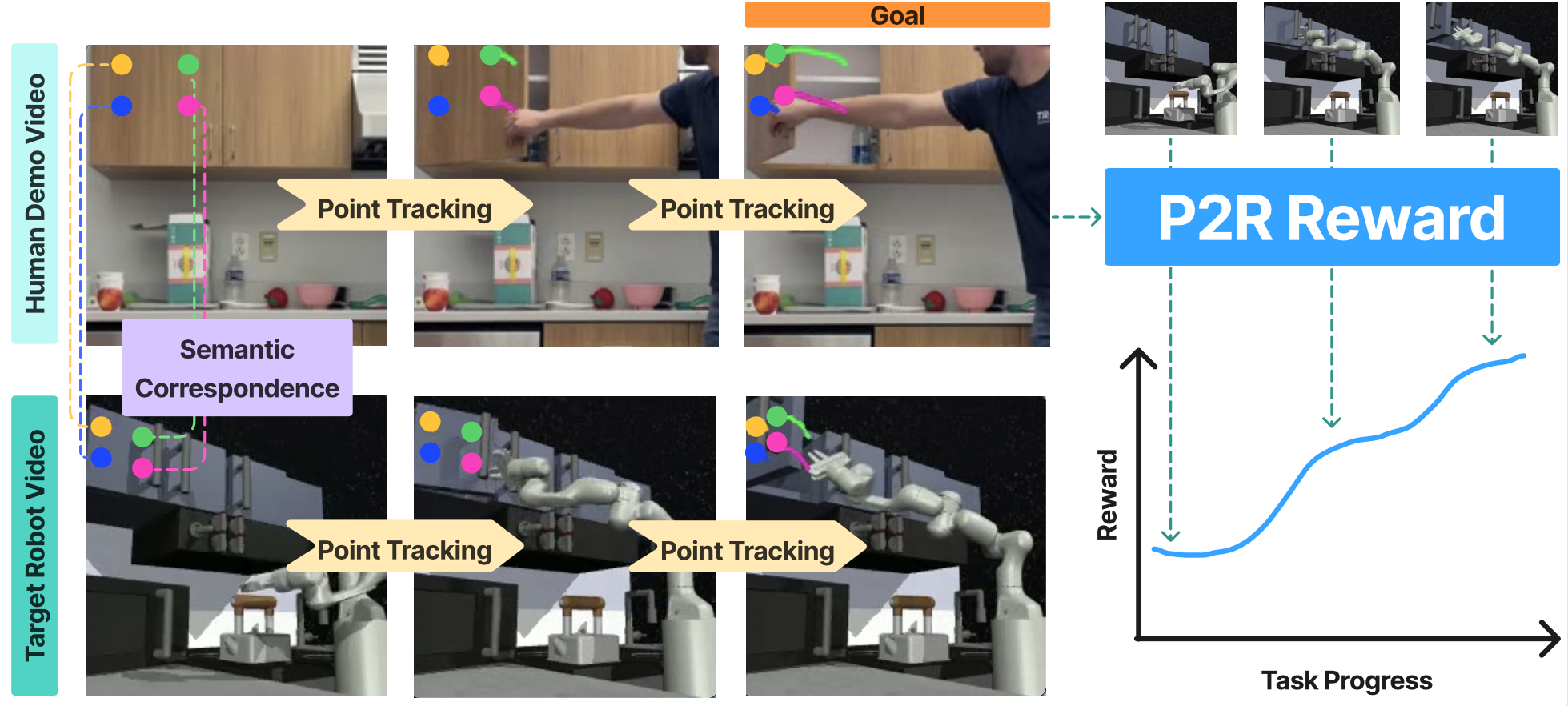
Detailed and dense reward functions provided clearly graded signals that enable a robot to evaluate and improve its policy, but generating such functions for new tasks is often cumbersome and expertise-intensive. On the other hand, end users can often easily record a video demonstrating the desired object trajectories and goal configurations involved in a new skill, but we lack methods to reliably learn from such a simple specification. We propose "Points2Reward" (P2R), which effectively computes dense rewards from a single video. To do this, P2R tracks task-relevant object points in task demonstrations and policy rollouts, and matches them to compare the desired and achieved object trajectories to generate reward scores. Exploiting recent advances in point tracking and semantic point correspondences, P2R produces high-quality rewards even under significant domain gaps between the demo video and the robot setup, such as embodiment gaps (human vs. robot) or camera viewpoint changes. We demonstrate that P2R correctly evaluates trajectories of varying quality in diverse real-world settings as well as in nine simulated manipulation tasks in standard benchmark suites. We further demonstrate that P2R policy evaluations enable improved downstream policy synthesis in the simulated tasks.